音视频及其数字化表示
声音和图像是两种不同的感知形式,它们的本质基于物理学的原理和感知机制。
声音和图像的本质
声音是由物体振动产生的机械波。当物体振动时,周围的空气分子也会振动,形成压缩和膨胀的波动。这种机械波通过空气传播,被耳朵中的鼓膜接收,然后通过听觉系统转化为我们能够感知的声音。
声音的特征由两个主要参数决定:频率和振幅。频率决定了声音的音调,而振幅则决定了声音的音量。
图像是通过光传递的信息。光是一种电磁波,当它照射到物体表面并反射进入眼睛或摄像机时,我们就能够感知到图像。
图像的特征由颜色和亮度决定。颜色是由光的频率决定的,而亮度是光的强度。在图像中,颜色和亮度分布形成了我们看到的场景。
通过对声音和图像进行数字化处理,可以将连续的模拟信号转换为离散的数字形式,以便更容易地存储、传输、处理和分析。
数字化的声音和图像,称为音频和视频,合称音视频。
音视频的原始数据是通过摄像机来采集的,音频通过麦克风收集,视频通过 CMOS 采集,数字化之后存储到磁盘里。
音频的数字化
采样。连续的模拟音频信号被以固定的时间间隔进行采样,得到一系列离散的采样值。采样的频率决定了每秒采样的次数,通常以赫兹(Hz)为单位。音频的常见采样率是 44.1kHz
量化,即用数字来表示音频幅度。量化深度,也称为采样精度,是模拟信号转换为二进制数字信号的位数。量化深度越高,采样的数字信号精度越高。比如,量化深度为 16 bit,采样的数字信号幅度就有
2^16 = 65536个档位。音频量化深度一般有 8 bit、16 bit、20bit、24bit 和 32bit 等。编码,即将量化后的数字转为二进制。常见的编码格式有
AAC,mp3,G711,opus。其中,opus免费开源,且编码效果好,底噪低,逐渐为流媒体所采用。

上图中,横坐标代表时间,1 秒钟内竖线的条数对应采样率,竖线的高度对应信号幅度,信号幅度的最小单位的倒数则是量化深度。
音频数字化的三要素
| 采样频率(sample rate) | 量化位数(bit depth) | 声道数(Number of Channels) |
|---|---|---|
| 每秒种抽取声音幅度样本的次数 | 每个采样点用多少二进制位表示数据范围 | 声音通道的个数 |
| 采样率越高,声音质量越高,数据量越大 | 量化位数越多,音质越好,数据量越大 | 立体声比单声道表现力更丰富,但数据量翻倍 |
| 常用的采样率: * 8,000 Hz - 电话所用采样率 * 11,025 Hz - AM调幅广播所用采样率 * 22,050 Hz - 无线电广播所用采样率 * 32,000 Hz - miniDV 所用采样率 * 44,100 Hz - 音频 CD 所用采样率 | * 8 bit,将幅度划分为 2^8 个等级 * 16 bit,共 65536 个量级,达到CD标准 * 32 bit,共 4294967296 个量级 | * 单声道并非意味着只有一个喇叭发声,通常会处理成两个喇叭输出同一个声道的声音 * 立体声两个喇叭都发声(通常左右声道有分工),更能感受到空间效果。 * 除了单双声道外,还有其他的更多声道,例如 5.1 、7.1 等等 |
视频的数字化
采样(Sampling): 视频信号是由连续的模拟图像构成的。在采样阶段,图像被以固定间隔的方式采样,将连续图像转换为离散像素点。1 秒中内采样的个数对应视频的帧率
量化(Quantization): 对于每个像素,图像的亮度和颜色被量化为数字值。这通常分为亮度量化和色度量化
色彩空间转换(Optional): 在某些情况下,视频信号可能需要在不同的色彩空间之间转换,例如从
RGB(Red, Green, Blue)到YUV(Luma, Chroma)。这通常是为了更有效地表示和传输图像信息。因为RGB色彩空间包含了很多人眼无法分辨的色值,且人眼对亮度(明亮度)的敏感性要远远高于对颜色(色度)的敏感性。Y(Luma)表示亮度,U和V(Chroma)表示颜色。通过将颜色信息分离到U和V分量,可以更有效地压缩颜色信息,使其更适合存储和传输编码(Encoding): 最后,编码阶段将量化后的数字值和可能的色彩空间信息以数字信号的形式编码,例如通过使用视频编解码器。常见的编码格式包括
AVC(H.264),HEVC(H.265),VP9,AV1
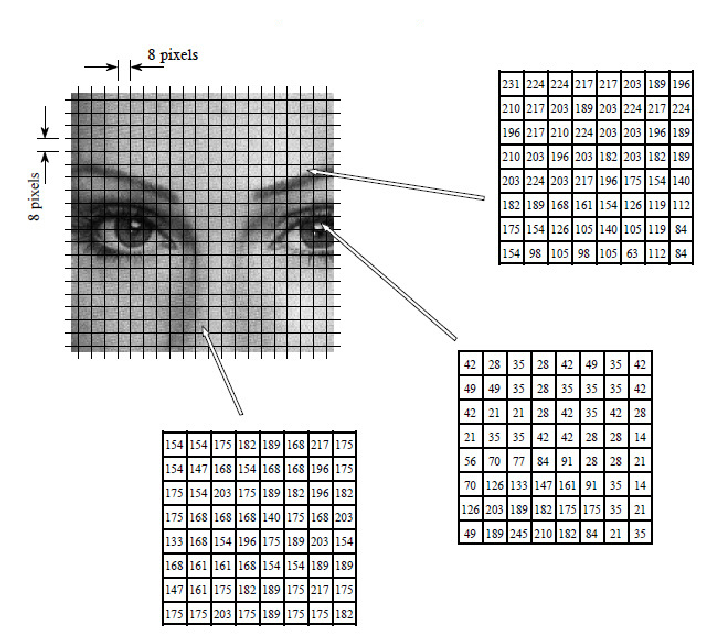
上图是 H.264 编码的示意图,每幅图像被分割成 8*8 像素尺寸来编码。
色彩空间
色彩空间(Color space)是对色彩的组织方式。色彩模型(Color model)是一种抽象数学模型,通过一组数字来描述颜色(例如RGB使用三元组、CMYK使用四元组)。由于“色彩空间”有着固定的色彩模型和映射函数组合,非正式场合下,这一词汇也被用来指代色彩模型。常见的色彩模型包括 RGB,YUV(YCbCr),HSV,HSL,CMYK 等。下面我们重点介绍 YUV 色彩模型。
YUV 是一种表示颜色的模型。但是我们常说的 YUV ,其实指的是 YCbCr,其中Y是指亮度分量,Cb指蓝色色度分量,而Cr指红色色度分量,是标准 YUV 的一个翻版,此文中,我们就用 YUV 指代 YCbCr 了。
YUV 格式按照数据大小分为三个格式,YUV 420,YUV 422,YUV 444。由于人眼对 Y 的敏感度远超于对 U 和 V 的敏感,所以有时候可以多个 Y 分量共用一组 UV,这样既可以极大得节省空间,又可以不太损失质量。
YUV 420,由 4 个Y分量共用一套UV分量YUV 422,由 2 个Y分量共用一套UV分量YUV 444,不共用,一个Y分量使用一套UV分量
在这三种类型之下,我们又可以按照 YUV 的排列储存顺序,将其细分为好多种格式。按照 YUV 的排列方式,再次将 YUV 分成三个大类,Planar,Semi-Planar 和 Packed。
- Planar YUV 三个分量分开存放
- Semi-Planar Y 分量单独存放,UV 分量交错存放
- Packed YUV 三个分量全部交错存放
封装格式(Byte Stream Format)
H.264 编码有两种 Byte Stream Format,分别是 AnnexB 和 AVCC。
1
2
3
4
AnnexB format:
([start code] NALU) | ( [start code] NALU) |
AVCC format:
([extradata]) | ([length] NALU) | ([length] NALU) |
In annexb, [start code] may be 0x000001 or 0x00000001. In avcc, the bytes of [length] depends on NALULengthSizeMinusOne in avcc extradata, the value of [length] depends on the size of following NALU and in both annexb and avcc format, the NALUs are no different.
Annex B多用于网络流媒体中:rtmp、rtp 格式,AVCC多用于文件存储中mp4的格式
H.265 编码和 H.264 不同,其 Byte Stream Format 包含 H.265 Annex B 和 H.265 Parameter Sets
使用 FFmpeg 查看视频文件信息
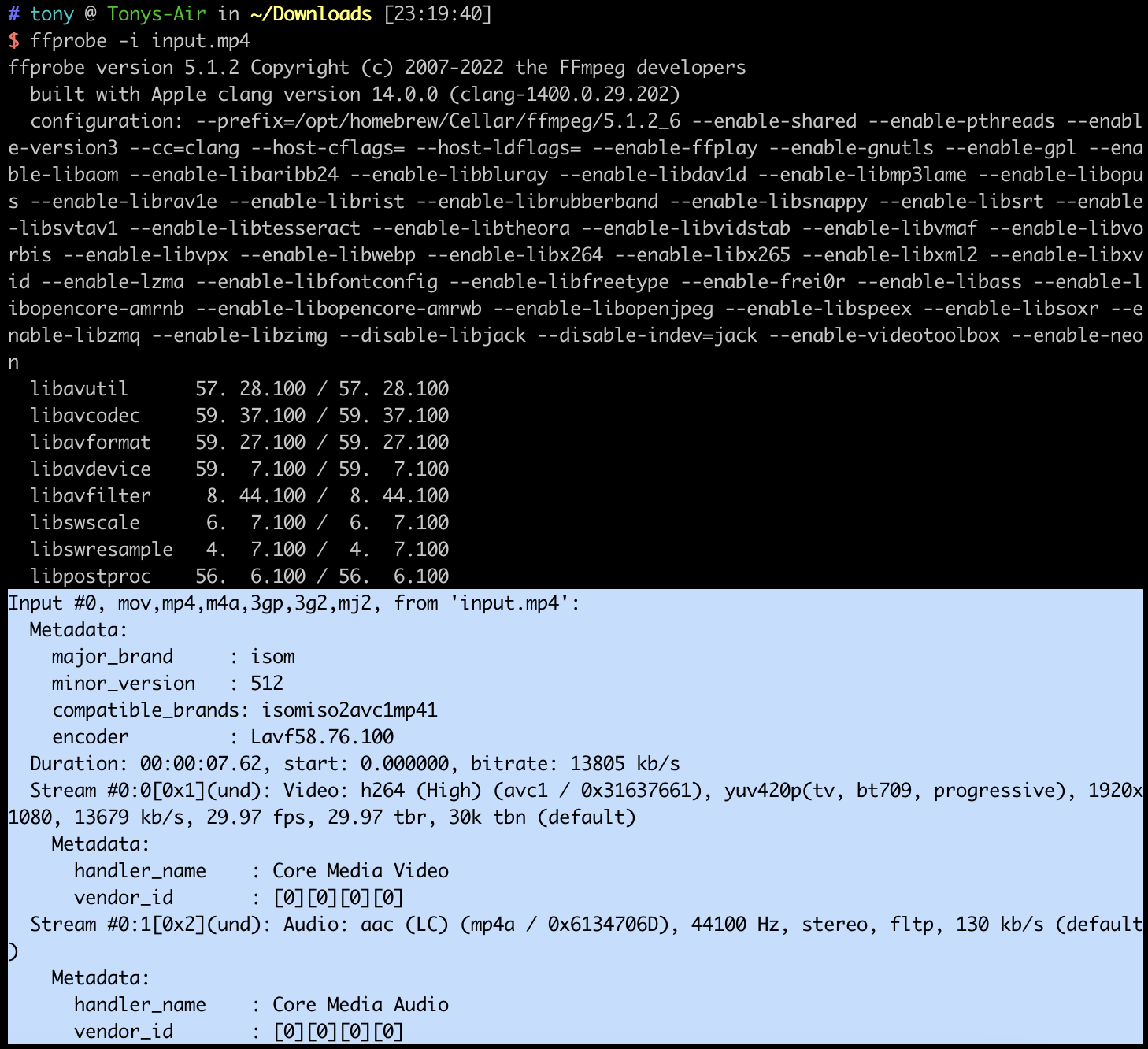
我们可以使用 ffmpeg 提供的 ffprobe 工具来查看视频文件信息。
从下图中高亮部分可以看到,该视频文件为 mp4 文件,时长 7.62 秒,码率为 13805 kb/s,包含了 2 条 Stream。
其中, Video 使用 H.264 编码,色彩空间为 yuv420,分辨率为 1080P(1920*1080),帧率为 29.97,
Audio 使用 aac 编码,采样率为 44.1kHz,立体声
1080p是一种视频分辨率标准,指的是视频的垂直分辨率为1080像素。具体来说,1080p视频的分辨率为1920x1080,其中1920是水平像素数,1080是垂直像素数。字母“p”代表“逐行扫描”(progressive scan)的意思。这意味着视频的每一帧都是通过扫描整个图像的每一行像素来创建的,而不是通过交替扫描奇数和偶数行像素来创建的。与交替扫描的“隔行扫描”(interlaced scan)相比,逐行扫描可以提供更清晰的图像,因为它可以更好地保留运动图像中的细节和清晰度。
问题思考:
- 高亮部分上面的一大串信息是什么?
- 什么是 yuv420 色彩空间?
- 为什么帧率不是整数?
留给后面的博客解答。^_^
参考资料
- https://www.volcengine.com/docs/6489/72015
- https://zh.wikipedia.org/zh-cn/%E8%89%B2%E5%BD%A9%E7%A9%BA%E9%96%93
- https://zhuanlan.zhihu.com/p/384455058
- ChatGPT