iOS 中的 Crash 探究
概述
Crash 是我们在日常使用 App 时偶尔会遇到的”闪退”,直接影响用户体验与留存。Crash 率是衡量 App 质量的重要指标之一。
通常主流 App 会将 Crash 率控制在万分之五以下,即每 10,000 次启动中 Crash 次数不超过 5 次。
本文围绕 iOS 生态,结合系统原理与实战经验,系统梳理 Crash 的:
- 本质:异常控制流程(ECF)的机制
- 成因:按出现频率排序的常见原因
- 传递流程:底层错误和上层语言错误的两条不同路径
- 排查方法:定位、复现、调试工具的使用
- 实战案例:KVO 与动态类创建的冲突问题
- 治理体系:监控、预防与质量保障
帮助开发者构建一套稳定的 Crash 质量保障流程。
一、Crash 的本质
1.1 异常控制流程(ECF)
Crash 本质是操作系统对异常情况的一种异常控制流程(Exception Control Flow, ECF)。当 CPU、内核或运行时检测到不可恢复的异常时,会触发控制流跳转到异常处理程序,最终可能导致进程退出。
ECF 可以发生在硬件、内核与应用层:
- 硬件层:硬件检测到事件(如外设中断)后通知 CPU
- 内核层:内核调度、上下文切换或信号派发
- 应用层:运行时或应用逻辑主动抛出异常、发送信号
移动 App 的 Crash 主要与内核层和应用层相关,因此下文聚焦这两层的处理机制。
1.2 操作系统的异常分类
操作系统会把异常划分为四类:中断(interrupt)、陷阱(trap)、故障(fault)和终止(abort)。该分类来自《深入理解计算机系统》第 8 章。虽然部分资料认为中断不属于异常,但从”程序未按原逻辑执行”的角度出发,可以将其视为广义异常的一部分。
| 类别 | 原因 | 异步/同步 | 返回行为 |
|---|---|---|---|
| 中断 | 来自 I/O 设备的信号 | 异步 | 总是返回到下一个指令 |
| 陷阱 | 有意的异常 | 同步 | 总是返回到下一个指令 |
| 故障 | 潜在可恢复的错误 | 同步 | 可能返回到当前指令 |
| 终止 | 不可恢复的错误 | 同步 | 不会返回 |
日常开发中最常见的导致 Crash 的是 fault,即潜在可恢复的错误。一旦故障无法被修复(如段错误访问非法内存),系统就会向进程发送信号或直接终止,从而表现为 Crash。常见的 EXC_BAD_ACCESS、SIGSEGV 都属于这一类。
1.3 应用层的异常保护
不同运行时拥有各自的异常体系。Java 的 JVM 通过 Throwable -> Error / Exception 抽象层级管理异常,绝大多数 Android Crash 都会被 JVM 捕获并转化为 Java 堆栈信息。
iOS 运行时(Objective-C Runtime / Swift Runtime)同样具备异常保护机制,例如:
unrecognized selector sent to instance:向对象发送未知消息时触发objc_exception_throw:Objective-C 抛出的NSException- Swift 层的
fatalError、preconditionFailure会触发SIGABRT
这些保护措施可以阻止异常直接掉到内核层,但当异常未被处理或升级为致命错误时,最终仍然会以 Crash 呈现。
二、Crash 的常见成因
App 发生 Crash 的原因多种多样,按照实际出现频率从高到低,主要可分为以下四类:
2.1 访问非法内存(最常见)
这是 iOS 开发中最常见的 Crash 类型,通常表现为 EXC_BAD_ACCESS 或 SIGSEGV。主要包括:
- 野指针:使用已释放的对象,或对象被释放后指针未置为
nil - 越界访问:数组、字符串等容器越界访问
- 多线程竞争:多线程下对同一内存的竞争写入,导致内存损坏
- 写保护内存:尝试修改只读内存区域(如字符串字面量)
在应用层面,可以借助内存布局图理解常见问题:

由低地址到高地址依次为:代码段(.text)→ 已初始化的数据(.data)→ 未初始化的数据(.bss)→ 堆(heap)→ 栈(stack)
内存布局说明:在大多数架构中,栈通常位于高地址区域,向低地址增长;堆位于栈下方,向高地址增长。不同架构的内存布局可能略有差异。
当进程在执行时,常见的 Crash 场景包括:
- 使用已释放对象(野指针)
- 多线程下对同一内存的竞争写入
- 越界访问数组或结构体
2.2 语言运行时保护机制触发
iOS 运行时(Objective-C Runtime / Swift Runtime)提供了异常保护机制,当检测到异常情况时会主动抛出异常或触发 Crash:
- 未识别消息:Objective-C Runtime 捕获
unrecognized selector sent to instance - 容器越界 / 插入
nil:Foundation 与 Swift 容器会主动抛出异常或调用fatalError - 类型断言失败:Swift 的
as!或try!失败时触发SIGABRT - 强制解包
nil:Swift 的!强制解包遇到nil时触发SIGABRT
底层语言如 C 并不提供这些保护,越界访问往往直接读写未定义内存。
语言保护差异:C 语言不提供运行时保护,越界访问不会立即 Crash,但会导致未定义行为,可能造成数据损坏或安全漏洞。而 Objective-C/Swift 的运行时保护机制会在检测到异常时主动抛出异常,虽然会导致 Crash,但能更早发现问题。
以下代码比较了 C 与 Objective-C 在数组越界时的不同表现:
1
2
3
4
5
6
7
8
9
10
11
int main () {
// C 语言:越界访问不会 Crash,但行为未定义
char str[6] = {'b','i','t','n','p','c'};
char c = str[6]; // 不会 Crash,但读取的是未定义内存
printf("%c\n", c); // 打印出的字符未知
// Objective-C:越界访问会 Crash
NSArray *array = @[@"b", @"i", @"t", @"n", @"p", @"c"];
id obj = array[6]; // Crash: index 6 beyond bounds [0 .. 5]
NSLog(@"%@\n", obj);
}
2.3 操作系统策略限制
iOS 系统会基于资源管理、安全策略等因素主动终止 App:
系统保护机制:这些策略是 iOS 系统保护用户体验和设备安全的重要手段。开发者需要理解这些机制,在开发时注意资源使用和性能优化,避免触发系统保护。
- WatchDog:系统监控主线程和应用启动时长,UI 主线程卡顿超过阈值或冷启动超时会被 WatchDog 杀死
- 内存压力:收到
didReceiveMemoryWarning但未及时释放资源,或后台 App 内存超标,系统会回收进程 - 热量与功耗:CPU/GPU 长时间高负载会触发系统降频甚至强制退出前台 App(相对少见)
- 代码签名 / 证书问题:企业证书过期、签名失效、越狱环境中签名校验失败等都会在启动阶段被系统终止
2.4 CPU 无法执行代码(相对少见)
这类 Crash 通常由底层硬件或指令级错误引起,在实际开发中相对少见:
- 非法算术运算:例如除以 0、浮点溢出等情况会触发
SIGFPE - 无效指令:运行时执行到未定义或架构不支持的指令,触发
SIGILL,常见于混用不同架构的二进制或错误的函数指针
三、Crash 捕获与传递流程
iOS 中的 Crash 传递有两条主要路径,取决于错误的来源:
路径一:底层错误(如野指针、访问非法内存)
- 硬件/内核检测到异常 → Mach 异常 → Unix Signal
- 这类错误直接由系统底层捕获,不经过语言运行时
路径二:上层语言错误(如数组越界、unrecognized selector)
- Objective-C/Swift Runtime 检测到 → NSException → 未捕获时调用
abort()→ SIGABRT - 这类错误由语言运行时主动抛出,如果未设置异常处理器,最终会通过
abort()触发信号
关键理解:理解这两条路径的区别非常重要。路径一的错误无法通过 NSException 捕获,必须注册信号处理器;路径二的错误可以通过 NSException 处理器获得更详细的错误信息(如异常名称、原因等),但如果不处理,最终也会触发信号。
为了更好地理解两条路径的区别,下面列出常见的 Crash 场景:
情况一:纯信号崩溃(无 NSException)
这类 Crash 直接由系统底层触发,不经过语言运行时,因此没有对应的 NSException,只能通过信号捕获:
- 野指针访问 →
SIGSEGV - 栈溢出 →
SIGTRAP - 内存限制 →
SIGKILL
情况二:NSException 触发的信号
这类 Crash 由语言运行时检测并抛出 NSException,如果未捕获则触发信号。需要通过 NSException 层来获得具体的错误信息:
- 数组越界 →
NSRangeException→SIGABRT - 消息转发失败 →
NSInvalidArgumentException→SIGABRT - Swift 可选值强制解包 nil →
NSException→SIGABRT
捕获策略:掌握这两条路径的区别,有助于在合适的层面注册处理器收集信息。通常需要在多个层次同时注册处理器(Mach 异常、Unix Signal、NSException),以补齐完整的上下文。最后,把捕获到的 CrashLog 符号化,转化为可读的堆栈信息。
3.1 Mach 异常
Mach 异常是最底层的内核级异常,如 EXC_BAD_ACCESS。在异常发生时,会被异常处理程序转换为 Mach 消息,接着依次投递到 thread、task 和 host 端口。
通过监听这些端口即可捕获 Mach 层的异常。下面以 PLCrashReporter 为例(此处仅列出关键代码),完整实现参见 PLCrashMachExceptionServer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 初始化 Mach 异常服务器上下文
// 1. 创建服务器端口
mach_port_allocate(mach_task_self(), MACH_PORT_RIGHT_RECEIVE, &_serverContext->server_port);
// 2. 创建通知端口
mach_port_allocate(mach_task_self(), MACH_PORT_RIGHT_RECEIVE, &_serverContext->notify_port);
mach_port_insert_right(mach_task_self(), _serverContext->notify_port,
_serverContext->notify_port, MACH_MSG_TYPE_MAKE_SEND);
// 3. 创建端口集合
mach_port_allocate(mach_task_self(), MACH_PORT_RIGHT_PORT_SET, &_serverContext->port_set);
// 4. 将服务器端口和通知端口加入端口集合
mach_port_move_member(mach_task_self(), _serverContext->server_port, _serverContext->port_set);
mach_port_move_member(mach_task_self(), _serverContext->notify_port, _serverContext->port_set);
// 5. 创建异常处理线程
pthread_create(&thr, &attr, &exception_server_thread, _serverContext);
开源方案如 PLCrashReporter、KSCrash 都是在底层注册 Mach 异常端口,提前截获异常并持久化堆栈,然后再交由系统继续传递,保证不会破坏默认行为。
重要说明:
- Mach 异常即使注册了对应的处理,也不会影响原先的传递流程。Mach 异常会继续传递到 Unix 层,转变为
Unix Signal- 如果 Mach 异常处理程序直接终止了进程,则对应的 Unix 信号可能不会产生
- 一个 Mach 异常通常对应一个或多个
Unix Signal
常见的 exception_type
| Exception 类型 | 描述 | 说明 |
|---|---|---|
EXC_BAD_ACCESS | Bad Memory Access | 错误内存地址,访问的地址不存在或者当前进程没有权限都会报这个错。常见于路径一(底层错误) |
EXC_CRASH | Abnormal Exit | 通常跟随的 UNIX Signal 是 SIGABRT,表示进程异常退出。常见于路径二(上层语言错误),当 NSException 未捕获导致 abort() 时 |
EXC_BAD_INSTRUCTION | Illegal Instruction | 非法或未定义的指令或操作数。常见于路径一(底层错误) |
3.2 Unix Signal
Unix Signal 是 Unix 系统的一种异步通知机制。对于底层错误(路径一),Mach 异常在 host 层被 ux_exception 转换为相应的 Unix Signal,并通过 threadsignal 将信号投递到出错的线程,如 SIGSEGV、SIGBUS。对于上层语言错误(路径二),NSException 未捕获时会调用 abort() 直接触发 SIGABRT。
在 Unix 层可使用 signal / sigaction 注册信号处理回调,将关键信息写入文件或上传至服务器。如下代码把接收到的 SIGBUS 统一用 signalHandler 处理:
1
2
3
4
5
6
7
8
9
10
11
12
void signalHandler(int sig) {
printf("signal %d received.\n", sig);
// 在这里可以保存堆栈信息、写入日志等
exit(1);
}
int main() {
signal(SIGBUS, signalHandler);
char *str = "bitnpc"; // 字符串字面量在只读段
str[0] = 'H'; // 尝试修改只读内存,触发 SIGBUS
return 0;
}
常见的 Unix 信号
下表列出了常见的 Unix Signal。在 macOS 系统中,可以输入 man signal 查看所有的 Signal 列表。在这里也可以看到。
| Unix Signal | 说明 |
|---|---|
SIGSEGV | 访问了无效的内存地址,这个地址存在,但是当前进程没有权限访问它。属于硬件层错误 |
SIGABRT | 程序异常终止,通常由 C 函数 abort() 触发,也可能由运行时断言失败、Swift 的 fatalError 等触发。属于软件层错误 |
SIGBUS | 访问了无效的内存地址,与 SIGSEGV 的区别是:SIGBUS 表示内存地址不存在。属于硬件层错误 |
SIGTRAP | Debugger 相关 |
SIGILL | 尝试执行一个非法的、未知的、没有权限的指令 |
3.3 NSException
NSException 是 Objective-C 运行时抛出的异常对象,通常由语言运行时保护机制触发(如数组越界、unrecognized selector 等)。通过 NSSetUncaughtExceptionHandler 注册处理函数,可以在崩溃前抓取异常名称、原因、调用栈并进行持久化。常见做法是在 handler 中将信息写入沙盒文件,待下次启动时再上报,避免在崩溃现场进行复杂逻辑。
警告:如果未设置异常处理器或处理器未阻止程序继续执行,未捕获的 NSException 会导致程序调用
abort(),从而触发SIGABRT信号。因此务必在 handler 中保存关键信息,避免在崩溃现场执行耗时操作。
如下代码展示了基础用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
void exceptionHandler(NSException *exception) {
// 获取异常信息
NSString *name = [exception name]; // 异常名称
NSString *reason = [exception reason]; // 出现异常的原因
NSArray *stackArray = [exception callStackSymbols]; // 异常的堆栈信息
// 持久化异常信息(写入文件或上传服务器)
NSLog(@"Exception: %@, Reason: %@", name, reason);
NSLog(@"Stack: %@", stackArray);
// 注意:不要在这里执行耗时操作,避免影响崩溃日志的完整性
}
int main(int argc, char * argv[]) {
// 注册未捕获异常处理器
NSSetUncaughtExceptionHandler(&exceptionHandler);
// 触发异常示例
NSArray *array = @[@"b", @"i", @"t", @"n", @"p", @"c"];
id obj = array[6]; // 触发 NSRangeException
return 0;
}
3.4 Crash Log 符号化
Crash 捕获后获得的数据都是对应的虚拟内存地址。我们需要把虚拟内存地址转化为可读的堆栈信息。符号化的本质是在一个映射文件中,找到内存地址对应的函数的方法名。
常见的符号化方式包括:
- Xcode Organizer / Devices 面板:自动符号化,适合本地调试
- symbolicatecrash 脚本:离线符号化,适合批量处理
- atos / atosl:根据地址定位符号,适用于自建平台
符号化最佳实践:项目代码的符号文件存储在
dSYM中,应在构建后及时归档并与版本号关联。系统库的符号可从 iOS 固件或第三方镜像获取。企业团队通常会在 CI 中集成符号文件上传,便于 Crash 平台(如 Firebase Crashlytics、腾讯 Bugly、Sentry、自研平台)自动解析。
四、Crash 排查思路
通常情况下,debug 时发生的 Crash 很好解决。但是,App 上线后,往往会出现一些本地没有遇到过,并且难以复现的 Crash。从 CrashLog 中往往不能直接定位问题所在,需要系统化的排查方法。
排查原则:线上 Crash 的排查需要耐心和系统化的方法。不要急于下结论,要收集足够的信息,尝试多种复现手段,必要时使用调试工具辅助定位。
4.1 定位阶段
- 收集线索:确认系统版本、App 版本、用户操作路径、堆栈、线程信息、设备型号、电量和网络环境等
- 还原场景:结合埋点或操作回放日志(如 Logan、Matrix)定位触发路径
- 快速对比:对比上一个版本的差异,关注近期合入的模块与实验开关
4.2 尝试复现
- 本地复现:利用断点回溯、开关控制精确命中崩溃路径
- 提升命中率:在 Xcode
Diagnostics中开启Malloc Scribble、NSZombie、Thread Sanitizer、Address Sanitizer等 - 多线程场景:编写脚本在多个线程中并发触发问题,提高复现概率
4.3 常用的内存调试工具
Malloc Scribble
原理是通过在已释放对象中填充 0x55,使得野指针调用必然崩溃。
使用限制:Malloc Scribble 仅本地
debug时有效,如果想在内测包中实现此功能,需要 hook 系统库中的free函数。
以如下代码为例(为便于说明,已关闭 ARC):
1
2
3
UIView *view = [UIView new];
[view release];
[view setNeedsLayout]; // 向已释放对象发送消息
很显然,此时 view 指向的对象已释放,但是 view 指针未置为 nil。所以我们在向一个已释放的对象发送了消息。但是,编译运行后,发现并不会 Crash。
打开 Malloc Scribble 后,可以从调试面板很清晰的看到,在第三行发生了 Crash。
Zombie Object
把已释放的对象标记为僵尸对象,Xcode 的实现方式是使用 runtime 方法 object_setClass,覆写被释放的 view 的 isa 为 _NSZombie_UIView。
除了上述 Memory Management 的工具,Xcode 还提供了 Runtime Sanitization 的工具(实际上是 LLVM 编译器提供的功能)。如可以监测竞态访问的 Thread Sanitizer,可以帮助开发者发现潜在的问题。
调试工具建议:在开发阶段充分利用 Xcode 的诊断工具,可以在问题上线前发现大部分内存和线程安全问题。建议在关键版本发布前,使用这些工具进行全面检查。
五、案例分析:KVO 与动态类创建的冲突
这是一个真实的生产环境 Crash 案例,展示了多线程环境下动态类创建与 KVO 机制的冲突问题。
案例背景:这是一个典型的线程安全问题,在多线程环境下动态创建类时,如果没有适当的同步机制,很容易导致 Crash。此类问题在生产环境中往往难以复现,需要仔细分析堆栈信息。
下面是一个真实的 CrashLog,为了便于阅读,省略了不相关的部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
Incident Identifier: 61590478-FA94-496E-9208-D2016678D6D0
CrashReporter Key: TODO
Hardware Model: iPhone7,2
Process: imeituan [10672]
Path: /var/containers/Bundle/Application/2140260F-0484-4CED-AC09-DEC9B620A63A/imeituan.app/imeituan
Identifier: com.meituan.imeituan
Version: 9.1.0 (3123)
Code Type: ARM-64
Parent Process: ??? [1]
Date/Time: 2018-11-12 08:44:34 +0000
OS Version: iPhone OS 10.1.1 (14B100)
Report Version: 104
Exception Type: SIGSEGV
Exception Codes: SEGV_ACCERR at 0x20
Crashed Thread: 22
Thread 22 Crashed:
0 libobjc.A.dylib objc_registerClassPair + 32
1 Foundation _NSKVONotifyingCreateInfoWithOriginalClass + 136
2 Foundation _NSKeyValueContainerClassGetNotifyingInfo + 80
3 Foundation -[NSKeyValueUnnestedProperty _isaForAutonotifying] + 84
4 Foundation -[NSKeyValueUnnestedProperty isaForAutonotifying] + 100
5 Foundation -[NSObject(NSKeyValueObserverRegistration) _addObserver:forProperty:options:context:] + 436
6 Foundation -[NSObject(NSKeyValueObserverRegistration) addObserver:forKeyPath:options:context:] + 124
7 imeituan -[NSObject(RACSelectorSignal) racSignal_addObserver:forKeyPath:options:context:] (NSObject+RACSelectorSignal.m:63)
8 imeituan -[RACKVOTrampoline initWithTarget:observer:keyPath:options:block:] (RACKVOTrampoline.m:50)
9 imeituan -[NSObject(RACKVOWrapper) rac_observeKeyPath:options:observer:block:] (NSObject+RACKVOWrapper.m:115)
10 imeituan __84-[NSObject(RACPropertySubscribing) rac_valuesAndChangesForKeyPath:options:observer:]_block_invoke.41 (NSObject+RACPropertySubscribing.m:0)
......
49 imeituan -[TPKxxxItem initWithText:jumpUrlString:] (TPKPOIDetailLookMoreCell.m:60)
50 imeituan -[TPKxxxViewModel itemsWithModel:] (TPKxxxViewModel.m:102)
51 imeituan __51-[TPKxxxViewModel setupViewModel]_block_invoke (TPKxxxViewModel.m:43)
......
5.1 问题分析
首先,来搜索一下堆栈信息。这里可供搜索的堆栈在 0-6 行。比如我们搜索 objc_registerClassPair,它是 runtime 创建类时调用的一个方法。但是这个信息不足以定位问题。
由堆栈第四行,搜索到了一片 KVO 创建同名类导致 Crash 的文章。但是,本项目是组件化的,每个 pod 都有不同的前缀,不存在不同二进制包中有多个符号并存的问题。
接下来,就看看能否复现。找到 TPKxxxViewModel 所对应的页面,发现没有发生 Crash。考虑到 Crash 的线程是后台线程,猜测很有可能是多线程创建 TPKxxxItem 导致的问题。那就可以写一些测试代码来尝试复现。注意,该段代码执行的时机要和实际创建该 item 一致。
1
2
3
4
5
6
// 多线程并发创建对象,尝试复现问题
for (int i = 0; i < 5; i++) {
dispatch_async(dispatch_get_global_queue(DISPATCH_PRIORITY_DEFAULT, 0), ^{
TPKxxxItem *item = [[TPKxxxItem alloc] initWithText:@"bit" jumpUrlString:@"npc"];
});
}
很幸运,成功复现。Crash 位置是项目中的一个基础库。查看该基础库的改动日志,发现多了一些 swizzle 的操作。该类有一个步骤类似于 KVO 的机制,过程中会创建一个新类。但是,后续又有 KVO 该类的操作。所以,我们的问题就转化为 KVO 在创建同名类的子类就会 Crash 的问题,正好契合前面搜集的资料。
5.2 KVO 机制解析
那么,为什么 KVO 在创建同名类的子类时会 Crash 呢?我们知道,KVO 主要做了以下几件事:
- 使用
objc_allocateClassPair和objc_registerClassPair方法,动态创建一个新类:NSKVONotifying_xxx,该类是原类的子类 - 将原对象的
isa指针指向新创建的NSKVONotifying_xxx类 - 把新类添加到全局的类表中
- 重写新类的 setter 方法,在 setter 中调用
willChangeValueForKey:和didChangeValueForKey:
在步骤一,如果创建两个同名的新类,会如何?可以写个测试代码验证一下:
1
2
3
4
5
6
7
8
9
- (void)applicationDidFinishLaunching:(NSNotification *)aNotification {
// 第一次创建同名类,成功
Class testClass1 = objc_allocateClassPair([NSObject class], "bitnpc_crash_test", 0);
objc_registerClassPair(testClass1);
// 第二次创建同名类,objc_allocateClassPair 返回 nil
Class testClass2 = objc_allocateClassPair([NSObject class], "bitnpc_crash_test", 0);
objc_registerClassPair(testClass2); // EXC_BAD_ACCESS: 传入 nil 导致崩溃
}
objc_allocateClassPair 时,返回的 class 为 nil。接着,用 objc_registerClassPair 注册新类时,由于传入的参数为 nil,导致了 crash。
再查看 objc-runtime 源码(objc4-723 版本),可以看出,如果 getClass(name) 返回的类不为空,则直接返回 nil,不分配新的内存空间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/***********************************************************************
* objc_allocateClassPair
* fixme
* Locking: acquires runtimeLock
**********************************************************************/
Class objc_allocateClassPair(Class superclass, const char *name,
size_t extraBytes)
{
Class cls, meta;
rwlock_writer_t lock(runtimeLock);
// Fail if the class name is in use.
// Fail if the superclass isn't kosher.
if (getClass(name) || !verifySuperclass(superclass, true/*rootOK*/)) {
return nil; // 类名已存在,返回 nil
}
// Allocate new classes.
cls = alloc_class_for_subclass(superclass, extraBytes);
meta = alloc_class_for_subclass(superclass, extraBytes);
// fixme mangle the name if it looks swift-y?
objc_initializeClassPair_internal(superclass, name, cls, meta);
return cls;
}
5.3 问题根源与解决方案
到这里,原因已经很清晰了。可以用以下流程图来表示:
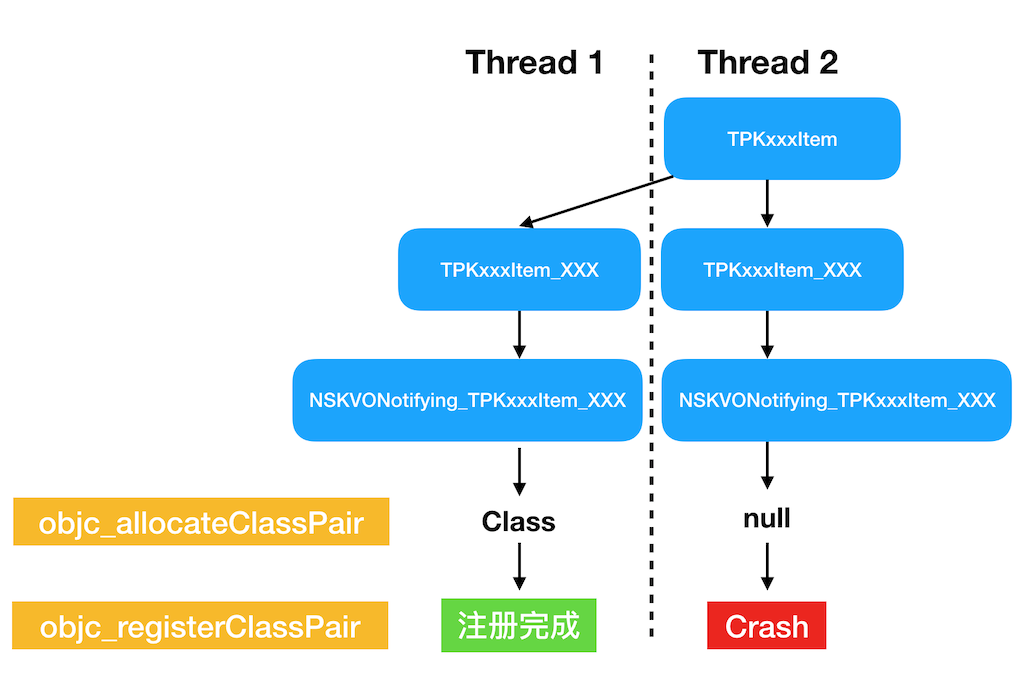
项目中某基础库创建了两个 TPKxxxItem_XXX,我们暂且称之为中间类。KVO 用这两个中间类创建子类时,因为没有分配到内存空间,导致 objc_registerClassPair 时,发生了 crash。
解决方案:在创建中间类时,对
self.class加锁,保证只生成一个中间类。使用dispatch_once或@synchronized都可以实现线程安全,推荐使用dispatch_once性能更好。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// 使用 dispatch_once 或加锁保证线程安全
static NSMutableDictionary *classCache = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
classCache = [NSMutableDictionary dictionary];
});
@synchronized(self.class) {
NSString *className = NSStringFromClass(self.class);
Class cachedClass = classCache[className];
if (!cachedClass) {
// 创建中间类
cachedClass = objc_allocateClassPair([self class], "TPKxxxItem_XXX", 0);
if (cachedClass) {
objc_registerClassPair(cachedClass);
classCache[className] = cachedClass;
}
}
return cachedClass;
}
注意事项:生成
TPKxxxItem_XXX没有 Crash 的原因是,多线程创建同名类时,objc_allocateClassPair不一定返回nil,这和底层容器的实现有关。该框架内部做了判断,当objc_allocateClassPair返回nil时,不执行 register 操作。但是 KVO 显然没有做这样的判断。
经验总结:在运行时动态生成类或方法时需注意线程安全与命名冲突,必要时加锁或使用串行队列,避免多线程下重复注册。这是 iOS 开发中常见的陷阱之一。
六、Crash 监控与治理体系
治理原则:Crash 治理是一个持续的过程,需要建立完善的监控、分析、修复、预防的闭环体系。关键是要在问题影响用户之前发现并解决。
- 核心指标:关注冷启动 Crash 率、活跃用户 Crash 率(DAU 崩溃用户占比)、场景 Crash 率(按页面 / 功能拆分),并结合卡顿、OOM 统计
- 采集策略:客户端在下次启动时上报 Crash 日志、线程堆栈、设备信息、最近操作,服务端聚合后计算指标
- 治理闭环:结合构建信息、灰度批次,对 Crash 进行分桶(首次出现、回归、核心路径),设定 SLA 与报警阈值
- 工具链:常见方案有 Crashlytics、Bugly、Sentry、自建基于 PLCrashReporter 的上报系统;配合 Xcode Organizer 与 App Store Connect 的
Metrics/Analytics交叉验证 - 预防机制:在内测包开启 ASan、TSan、Malloc Guard、Zombie 等调试工具;使用静态检查(Clang Static Analyzer、Infer)与单元测试覆盖关键模块;上线后利用 Feature Flag 快速降级
七、总结
本文结合操作系统异常控制机制,梳理了 Crash 的本质、常见成因、传递流程、捕获层次与符号化方法,并给出排查思路与实际案例。
质量保障体系:要持续降低 Crash 率,需要在开发期做好前置防护、上线期完善监控与回归测试、运营期保持指标跟踪与快速止损,形成自上而下的质量闭环。这是一个系统工程,需要团队协作和持续改进。
关键要点回顾
- Crash 本质:异常控制流程(ECF),从硬件层到应用层的多层异常处理机制
- 常见成因(按频率排序):访问非法内存(最常见)→ 语言运行时保护机制 → 操作系统策略限制 → CPU 无法执行代码(相对少见)
- 传递流程:有两条主要路径
- 路径一(底层错误):Mach 异常 → Unix Signal
- 路径二(上层语言错误):NSException →
abort()→ SIGABRT - 需要在多个层次注册处理器以捕获完整信息
- 排查思路:收集线索 → 还原场景 → 尝试复现 → 定位问题 → 修复验证
- 最佳实践:线程安全、命名规范、监控体系、工具链建设