Claude Code Dynamic Workflow 深度解析
Dynamic Workflow 的本质是 AI 驱动的分治法——Claude 动态生成”分解-并行求解-验证-合并”的编排脚本,由独立运行时执行,从而突破单 Agent 的上下文、并行度和验证能力瓶颈。
一、背景
2026 年 5 月 28 日,Anthropic 发布了 Dynamic Workflow 能力:
Claude dynamically writes orchestration scripts, fans work out across tens to hundreds of parallel subagents, and verifies its own results before presenting them.
为什么值得关注?Anthropic 公开的标杆案例——Bun 项目从 Zig 重写为 Rust:
- 代码规模:~75 万行
- 耗时:11 天
- 测试通过率:99.8%
这标志着 Claude Code 在自主规划和大型复杂项目的工程能力上更进一步。
二、技术原理
2.1 Claude Code 原始架构:Agent Loop
根据论文《Dive into Claude Code: The Design Space of AI Agent Systems》,Claude Code 的核心是一个响应式 while-loop:
The core of the system is a simple while-loop that calls the model, runs tools, and repeats.
执行流程:上下文组装 → 模型调用 → 工具路由 → 权限校验 → 执行 → 压缩 → 循环。
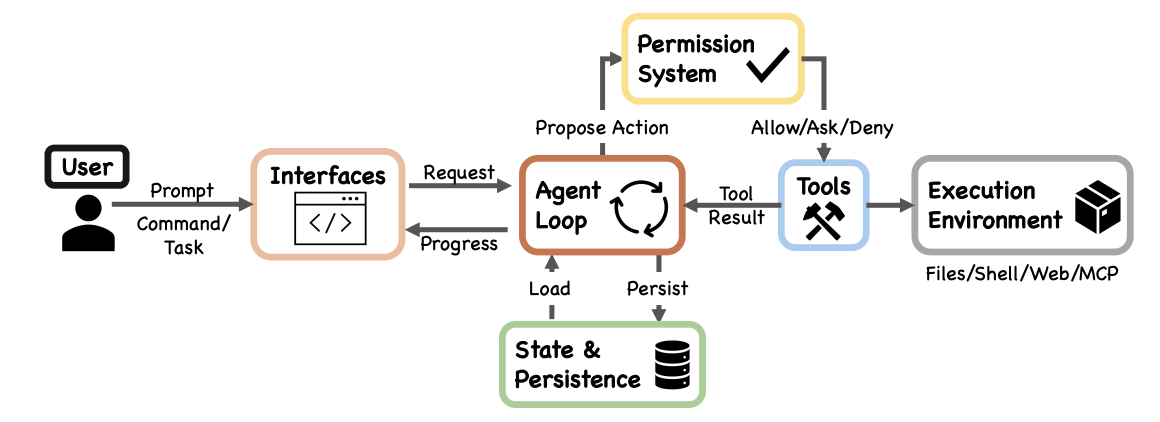
关键特点:
- 统一性:无论 CLI、IDE 还是 Agent SDK,都运行同一个
queryLoop()函数 - 已有子 Agent 能力:subagent 通过 Agent Tool 被调用,本质是”带隔离上下文的 queryLoop() 实例,只返回摘要给父 Agent”
- 关注点分离:核心循环保持简洁,Permission、Execution Environment 等复杂性封装在外围模块
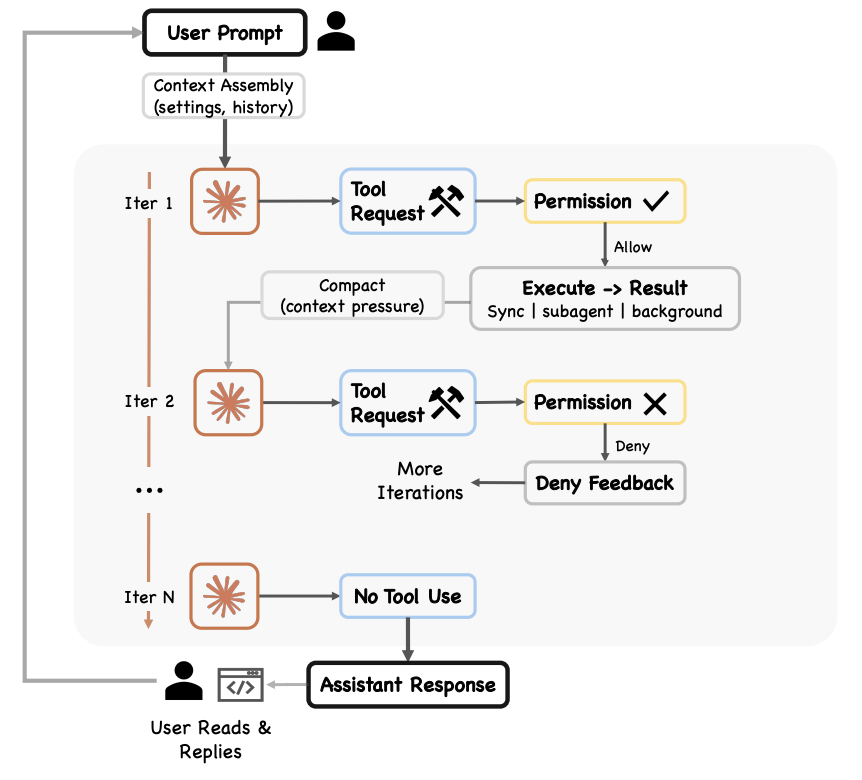
2.2 单 Agent 循环的问题
虽然 Claude Code 已具备 subagent 能力,但原有模式下编排决策仍由 Main Agent 逐轮推理完成。Claude 在单个上下文窗口中处理复杂任务的时间越长,就越容易出现以下失败模式:
- Agentic 惰性(Agentic laziness):在完成特别复杂的多部分任务之前就停下来,在部分进展后宣布工作完成。例如安全审查中只处理了 50 项中的 20 项。
- 自我偏好偏差(Self-preferential bias):倾向于偏好自己的结果或发现,尤其是被要求验证或判断它们时。
- 目标漂移(Goal drift):在多轮对话中(尤其是压缩之后),对原始目标的忠实度逐渐丧失。每个摘要步骤都是有损的,边缘情况需求或”不要做 X”等约束可能会丢失。
2.3 Dynamic Workflow 的架构
Dynamic Workflow 通过将编排决策外化到独立脚本来结构性解决上述三个问题——每个子代理拥有独立上下文(解决惰性和目标漂移),独立验证代理互相审查(解决自我偏好偏差)。
核心思路:不改 Agent Loop 本身,而是将”编排决策”从 Claude 的推理中外化到独立的脚本运行时。
官方文档的关键定义:
A dynamic workflow is a JavaScript script that orchestrates subagents at scale. Claude writes the script for the task you describe, and a runtime executes it in the background while your session stays responsive.
With subagents and skills, Claude is the orchestrator. A workflow script holds the loop, the branching, and the intermediate results itself, so Claude’s context holds only the final answer.
2.4 Workflow Runtime
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
┌──────────────────────────────────────────────────────────┐
│ Claude Code Session │
│ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ Main Agent (queryLoop) │ │
│ │ │ │
│ │ 用户输入 → 推理 → 工具调用 → 观察 → 循环 │ │
│ │ │ │ │
│ │ ┌──────────┴──────────┐ │ │
│ │ ▼ ▼ │ │
│ │ [普通工具调用] [Workflow Tool] │ │
│ │ Read/Edit/Bash/ 生成 JS 编排脚本 │ │
│ │ Agent Tool... 交给独立 Runtime │ │
│ └───────┬──────────────────────┬───────────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────┐ ┌─────────────────────────────┐ │
│ │ Subagent │ │ Workflow Runtime │ │
│ │ (queryLoop) │ │ (独立隔离环境) │ │
│ │ │ │ │ │
│ │ - 隔离上下文 │ │ JS脚本持有: │ │
│ │ - 返回摘要 │ │ - 循环/分支逻辑 │ │
│ │ - Claude逐轮 │ │ - 中间结果(脚本变量) │ │
│ │ 决定下一步 │ │ - phase()阶段划分 │ │
│ │ │ │ │ │
│ └──────────────┘ │ 批量派发 subagent: │ │
│ │ ┌──┐┌──┐┌──┐...×N │ │
│ │ │A ││B ││C │ │ │
│ │ └┬─┘└┬─┘└┬─┘ │ │
│ │ ▼ ▼ ▼ │ │
│ │ 各自运行 queryLoop() │ │
│ │ (隔离上下文,返回结果) │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ 脚本继续:验证/聚合/迭代 │ │
│ └──────────┬─────────────────┘ │
│ │ │
│ ▼ │
│ 最终结果返回 Main Agent │
└──────────────────────────────────────────────────────────┘
关键点:
- Agent Loop(queryLoop)没有被替换——每个 subagent 底层仍是 queryLoop 实例
- 新增的是 Workflow Runtime:一个独立的脚本执行环境
- 编排决策从”Claude 推理中”移到”脚本代码中”
- 中间结果存在脚本变量中,不进入任何 Agent 的上下文窗口
- 主会话在工作流运行期间保持响应可用
2.5 并发模型与算法思想
并发模型:单进程、异步并发
Claude Code 是 Node.js/TypeScript 应用,天然适合异步并发(async/await)。并发上限公式为 min(16, cpu cores - 2)——受 API 调用限流、内存占用、CPU 密集的上下文组装多重因素约束,本地计算资源是主要瓶颈之一。官方说的”isolated environment”指逻辑隔离(独立上下文/变量作用域),最可能的模型是单进程、异步并发调度,类似容量为 16 的 async task pool。
算法思想:分治 + DAG
Dynamic Workflow 的编排模型本质是 DAG(有向无环图)执行——支持依赖关系和结果传递,核心思想是分治法。
| 算法思想 | 适用性 | 说明 |
|---|---|---|
| 分治法 | ✅ 完全适用 | 大任务拆分为独立子任务,并行求解,合并结果 |
| 备忘录/缓存 | 🟡 部分具备 | 脚本变量天然是”备忘录”;恢复时已完成 agent 返回缓存结果不重跑 |
| 拓扑排序 | 🟡 可通过脚本实现 | 先计算公共依赖,再并行处理独立任务 |
| 动态规划 | ❌ 状态转移不适用 | 但”缓存已解子问题”的思想通过脚本变量天然具备 |
对于有公共依赖的场景,正确做法是在脚本中显式提取公共步骤:
1
2
3
4
5
6
7
8
// 先求解公共子问题
const sdkAnalysis = await agent("分析 SDK 公共接口定义和约束")
// 再并行求解独立子问题,传入公共结果
const results = await pipeline(
plugins,
plugin => agent(`基于以下约束审查 ${plugin}: ${sdkAnalysis}`)
)
这是 DAG 中的依赖关系处理(拓扑排序)。
适用前提:Dynamic Workflow 最适合子任务间相互独立的场景(纯分治);存在公共依赖时需 AI 在生成脚本时识别并显式编排;存在强顺序依赖或共享可变状态时分治策略本身不适用。
2.6 与其他编排方案的本质区别
Claude Code 官方文档将编排能力分为四个层次,按”谁持有计划”区分:
| 维度 | 原有 Subagent | Skills | Agent Teams | Dynamic Workflow |
|---|---|---|---|---|
| 本质 | Claude 派发的工作者 | Claude 遵循的行为模式 | 人工预定义的角色组织 | 运行时执行的 JS 脚本 |
| 编排者 | Main Agent(Claude 推理) | Claude(受 Skill 指导) | 人工代码 | JS 脚本(AI 生成) |
| 决策方式 | Claude 逐轮决定下一步 | Claude 按 Skill 模板决策 | 预定义流程固定执行 | 脚本持有循环和分支 |
| 中间结果 | 落入 Claude 上下文 | 落入 Claude 上下文 | 各 Agent 上下文 | 脚本变量(不占上下文) |
| 规模 | 每轮几个 | 每轮几个 | 固定角色数量 | 数十到数百个/次 |
| 结构生命周期 | 每轮重新决策 | 会话内有效 | 部署前固定 | 每次任务动态生成后销毁 |
| 适用规模 | 小任务委托 | 10-20 步结构化任务 | 中等复杂度固定流程 | 大规模并行(500+文件) |
| 类比 | 一个人临时叫帮手 | 一个人按 SOP 做事 | 固定组织架构 | 项目制临时团队 |
三、工作模式
工作模式本质上是 Dynamic Workflow 执行时对应的 DAG 的拓扑结构。
以下是 Claude 在构建工作流时常用的几种模式。
3.1 分类并执行(Classify-and-act)
核心思路:先判断”是什么”,再决定”怎么做”。
使用分类器 Agent 判断任务类型,然后路由到不同的处理逻辑、Agent 或模型。也可在流程末尾使用分类器决定输出格式。
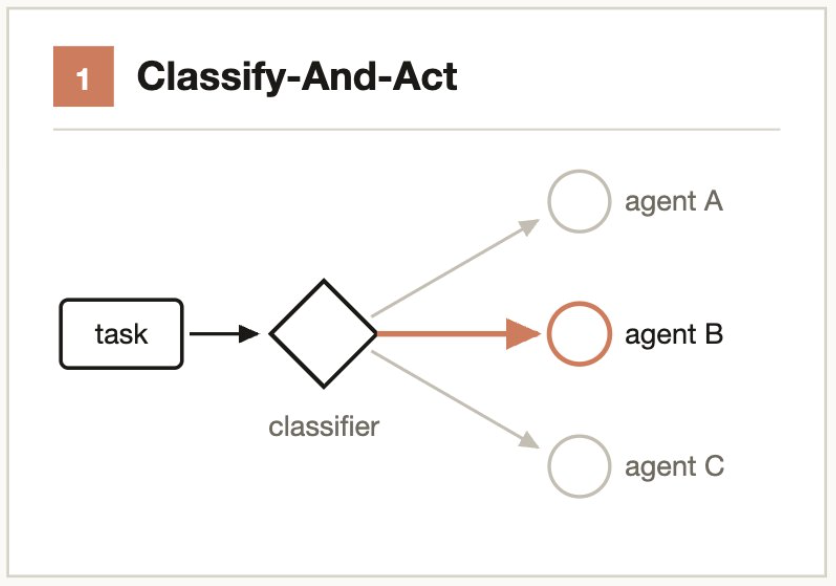
1
2
3
典型场景:
- 支持工单 → 分类 Agent 判断严重程度 → 路由到"自动修复"或"升级人工"
- 代码变更 → 分类 Agent 评估复杂度 → 路由到 Sonnet(简单)或 Opus(复杂)
3.2 扇出并综合(Fan-out-and-synthesize)
核心思路:拆分 → 并行求解 → 屏障等待 → 合并结果。
将任务拆分为多个独立子步骤,每个步骤分配独立 Agent 处理。综合步骤(synthesize)是一个屏障(barrier)——等待所有扇出 Agent 完成后,合并结构化输出为最终结果。
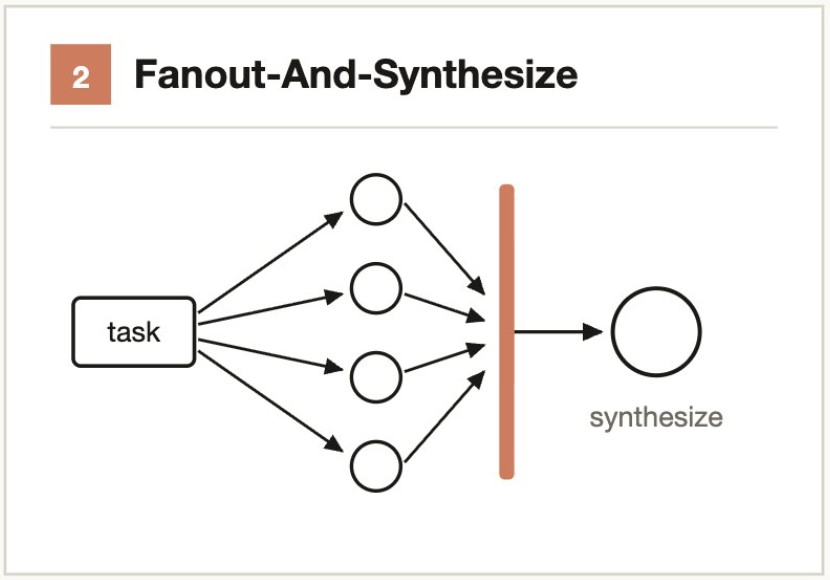
适用时机:子步骤数量多,或每步需要干净上下文窗口避免交叉污染。
1
2
3
典型场景:
- 审计 50 个 API 端点 → 每个端点 1 个 Agent → 汇总生成审计报告
- 分析 20 个模块的性能 → 并行 profiling → 综合排出优化优先级
3.3 对抗性验证(Adversarial verification)
核心思路:让”怀疑论者”尝试推翻每一个发现。
为每个产出 Agent 的结果运行独立的验证 Agent,该验证 Agent 被要求尝试反驳(而非确认)。多数投票决定结论是否成立。
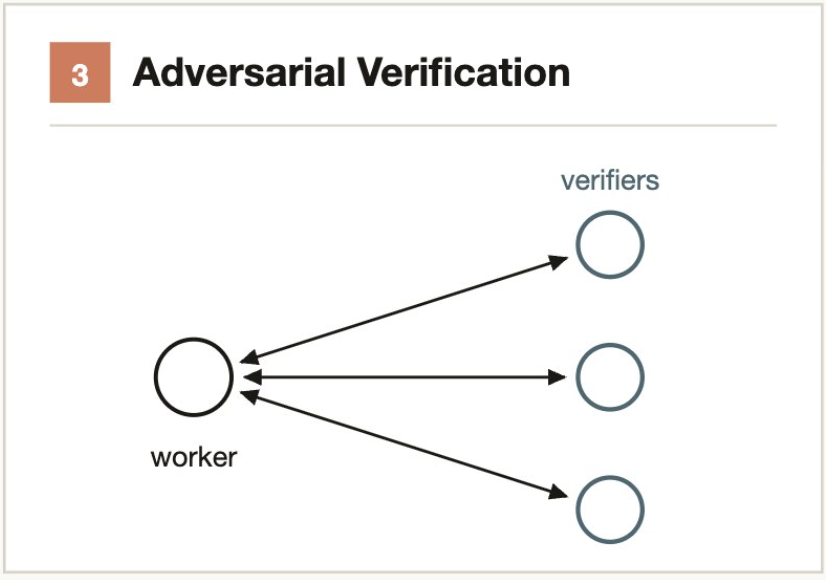
解决的问题:单 Agent 的自我偏好偏见——自己验证自己的结果几乎不会发现问题。
1
2
3
典型场景:
- Agent A 发现安全漏洞 → Agent B 被提示"尝试证明这不是漏洞" → 3 票中 2 票确认为真
- 代码审查发现 5 个 Bug → 每个 Bug 由独立 Agent 尝试构造反例
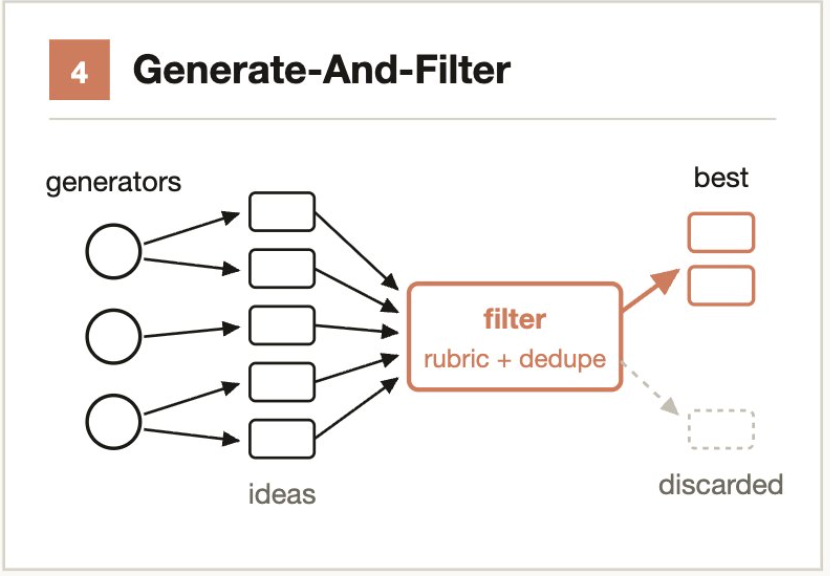
3.4 生成并过滤(Generate-and-filter)
核心思路:宁多勿少生成,严格标准过滤。
大量生成候选方案,然后通过验证、去重和评分过滤,只保留高质量、经过测试的结果。
1
2
3
典型场景:
- 为 CLI 工具想 50 个名字 → 去重 → 按可用性/含义/发音过滤 → 保留前 5 个
- 生成 20 种架构方案 → 按性能/可维护性/成本打分 → 精选 3 个供评审
3.5 锦标赛(Tournament)
核心思路:不分工,而是竞争。两两比较比绝对评分更可靠。
生成 N 个 Agent,每个用不同方法尝试同一任务。然后由评判 Agent 以成对方式(pairwise comparison)逐轮评判,直到产生优胜者。
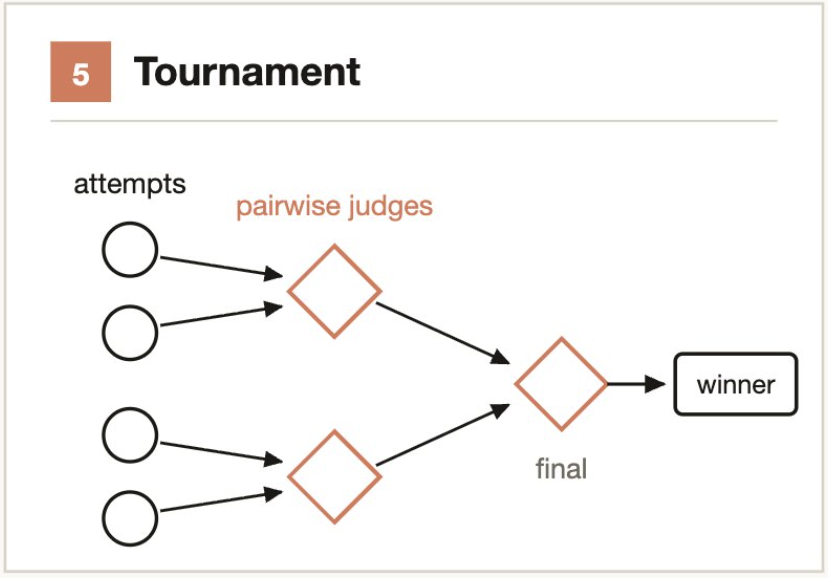
为什么比打分好:人(和 AI)在”A 比 B 好”这种相对判断上远比”给 A 打 8.2 分”这种绝对评分更准确。
1
2
3
典型场景:
- 3 个 Agent 分别用不同架构实现缓存方案 → 评判 Agent 两两对比 → 选出最优
- 1000+ 条支持工单按严重程度排序 → 锦标赛式两两比较 → 输出有序列表
3.6 循环直到完成(Loop until done)
核心思路:不设固定次数,而是设停止条件。
对于工作量未知的任务,循环派发 Agent 直到满足停止条件(连续 K 轮无新发现、日志中无新错误、测试全部通过),而非使用固定的遍历次数。
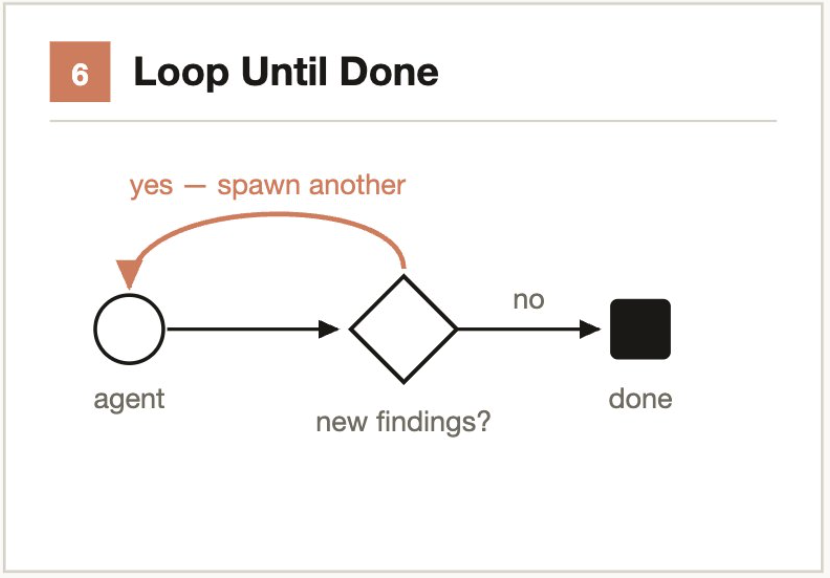
解决的问题:固定次数可能过早停止(遗漏长尾问题)或过晚停止(浪费 Token)。
1
2
3
典型场景:
- 持续挖掘代码库安全漏洞 → 连续 2 轮无新发现 → 停止
- 迭代修复 lint 错误 → 直到 lint 命令输出 0 errors → 停止
实际工作流通常组合多种模式。例如大规模 Code Review = 扇出并综合(按模块拆分)+ 对抗性验证(每个发现由怀疑论者审查)+ 循环直到完成(持续发现直到无新问题)+ 分类并执行(按严重程度分类输出)。
四、使用场景
4.1 迁移和重构
主要模式:扇出并综合 + 对抗性验证
将任务分解为需要逐一操作的单元(调用点、失败测试、模块),为每个修复在 worktree 中启动独立 Agent,再由另一个 Agent 进行对抗性审查后合并。
告知 Agent 不要使用资源密集型命令(如完整构建),以便最大化并行度而不耗尽机器资源。
标杆案例:Bun 项目从 Zig 重写为 Rust——75 万行代码,11 天完成,测试通过率 99.8%。
4.2 深度验证
主要模式:扇出并综合 + 对抗性验证
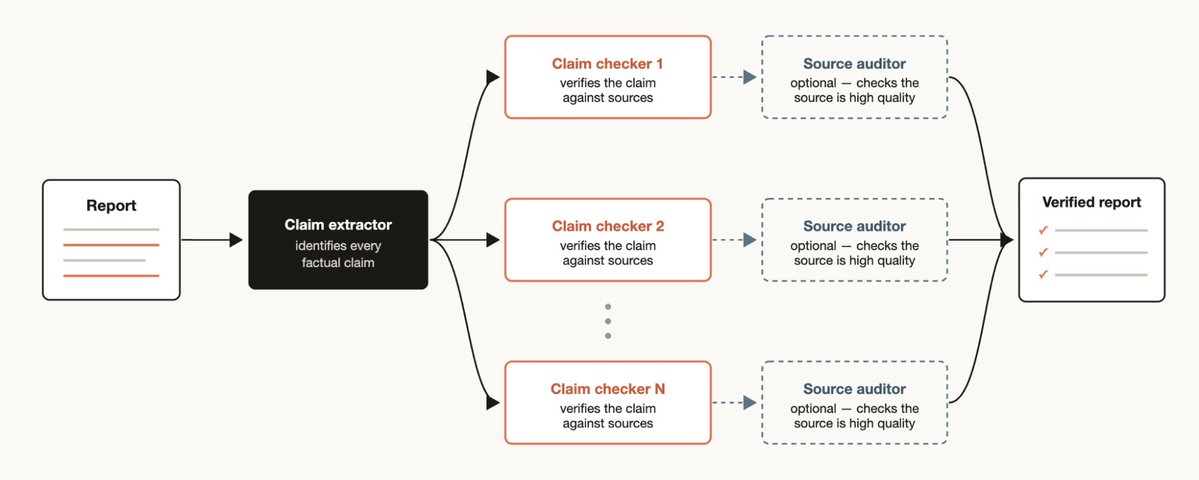
当你有一份报告需要检查其中引用的每一个事实声明:
1
2
3
4
5
工作流结构:
1. 声明识别 Agent → 提取报告中所有事实声明
2. 为每个声明启动来源查找 Agent → 查找支撑证据
3. 验证 Agent → 检查来源 Agent 找到的证据是否高质量
4. 综合 → 标注每条声明的验证状态(已验证/未验证/存疑)
4.3 排序
主要模式:锦标赛
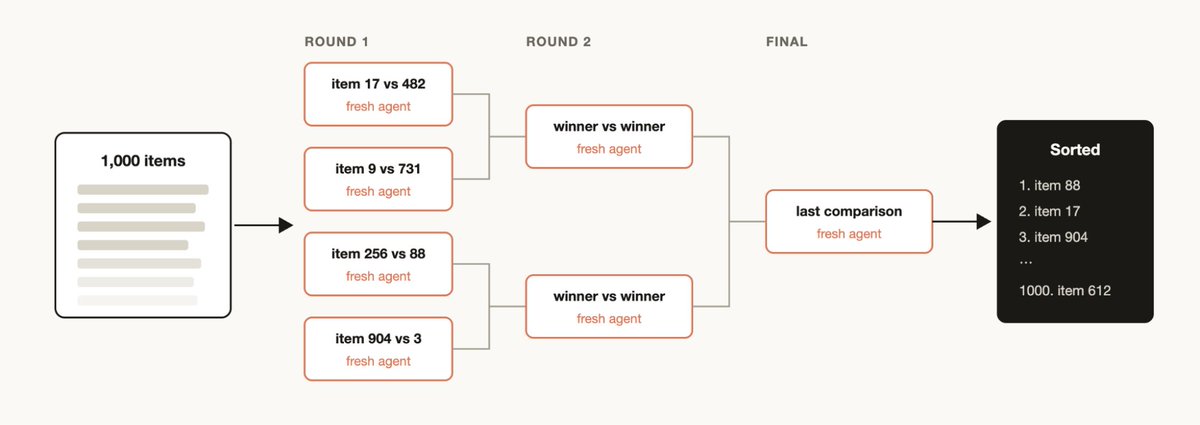
对大量项目按定性指标排序(如按 Bug 严重程度排序 1000+ 条支持工单)。单次提示无法处理这个规模且质量下降。
推荐方法:
- 锦标赛:两两比较(比较判断比绝对评分更可靠),每次比较是独立 Agent
- 分桶 + 合并:先并行分桶排名,再合并各桶
- 确定性循环持有赛程表,只有运行顺序保留在上下文中
4.4 记忆和规则遵守
主要模式:扇出并综合 + 对抗性验证 + 生成并过滤
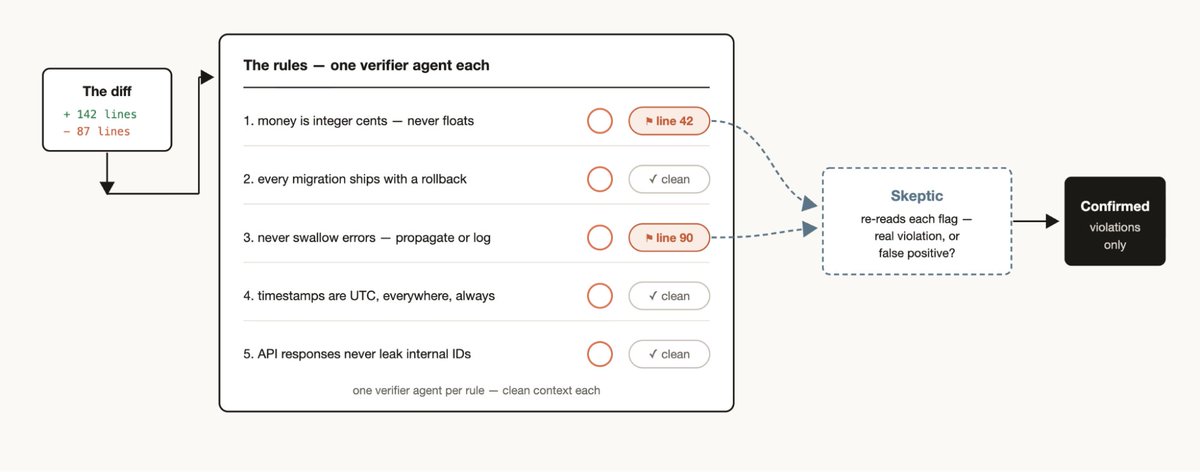
当你发现 Claude 反复违反某些规则(即使写在 CLAUDE.md 中):
正向强制:创建工作流,为每条规则分配一个验证器 Agent。配合”怀疑论者”Agent 审查,避免误报过多。
反向挖掘:
1
2
3
4
1. 挖掘最近 50 个会话和 Code Review 中反复做出的修正
2. 并行 Agent 对修正进行聚类
3. 对抗性验证每个候选规则("这条规则是否真能防止错误?")
4. 将幸存者提炼写入 CLAUDE.md
4.5 大规模分诊
主要模式:分类并执行 + 循环直到完成
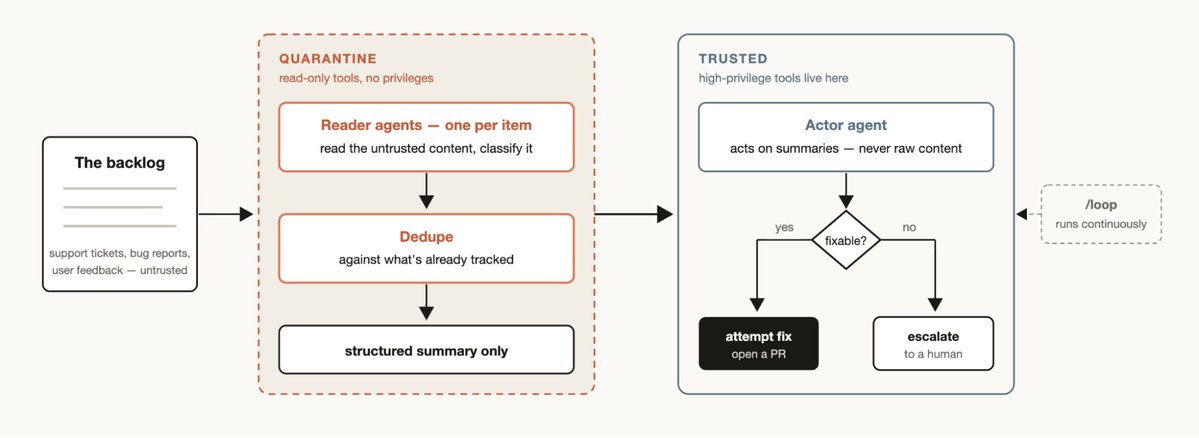
每个团队都有积压的支持队列、Bug 报告或其他无法由人工完全处理的待办。
分诊工作流三步:分类 → 与已跟踪项去重 → 采取行动(自动修复或升级人工)。
隔离模式(Quarantine):读取不可信公开内容的 Agent 禁止执行高权限操作(如写数据库、发通知),高权限操作由专门的行动 Agent 负责。这是安全分治原则。
持续化:配合 /loop 让 Claude 持续自动分诊,实现”永不停歇的值班 Agent”。
4.6 不推荐场景
- 修复单个简单 Bug——启动工作流的开销远大于收益
- 强时序依赖或共享状态——分治思想不再适用
- Token 预算紧张的日常开发——官方明确提示 “a single run can use meaningfully more tokens than working through the same task in conversation”
判断原则:如果任务可以在一个上下文窗口中被一个 Claude 高质量完成,不要强制使用工作流。工作流的价值在于推动 Claude 做以前做不到的事,而非给简单任务增加不必要的复杂度。
五、研发落地场景
5.1 大规模 Code Review
业务背景:大型代码库规模大、模块多,日常 MR 涉及多个业务线,人工审查耗时且维度有限。
应用方式:每个模块分配独立 Agent 并行审查——设备控制/安全性、网络通信/协议合规、UI 组件/一致性、数据存储/隐私合规、自动化场景/逻辑完整性。Verifier Agent 对发现的问题进行对抗性验证,过滤误报。
预期收益:大型 MR 审查从数小时缩短到分钟级,覆盖维度更全面。可保存为团队标准工作流(.claude/workflows/),通过 /<name> 复用。
当前的 AI Reviewer 本质是单一 Prompt 审查。升级为 Dynamic Workflow 后,可按维度(编码风格、架构合理性、安全性、性能、并发安全、UI 规范)分别派发专项 Agent,最后由 Aggregator 汇总为结构化审查报告。
5.2 技术栈迁移
业务背景:App 持续进行技术现代化,典型的迁移任务包括 Objective-C → Swift、旧版本 API → 新框架、旧埋点方案 → 新数据采集 SDK。
应用方式:每个文件/模块分配独立 Agent 并行迁移,Verifier Agent 验证迁移后功能等价性。Bun 案例(75 万行 / 11 天 / 99.8%)验证了此模式的可行性。
5.3 安全与隐私合规审计
业务背景:IoT 设备控制涉及大量敏感数据(设备 Token、用户隐私、家庭信息),合规要求严格。
审计维度(每个维度一组 Agent):
- 权限校验完整性
- Token/密钥硬编码或泄露风险
- 网络通信加密合规性
- 用户数据存储合规性(GDPR/个保法)
- 第三方 SDK 权限审查
关键价值:对抗性验证大幅降低误报率,多维度并行确保无遗漏。
5.4 测试覆盖率提升
应用方式:并行分析未覆盖代码路径 → 每个 Agent 为一个模块生成单元测试 → Verifier Agent 校验测试质量和有效性。
六、使用方式
6.1 触发方式
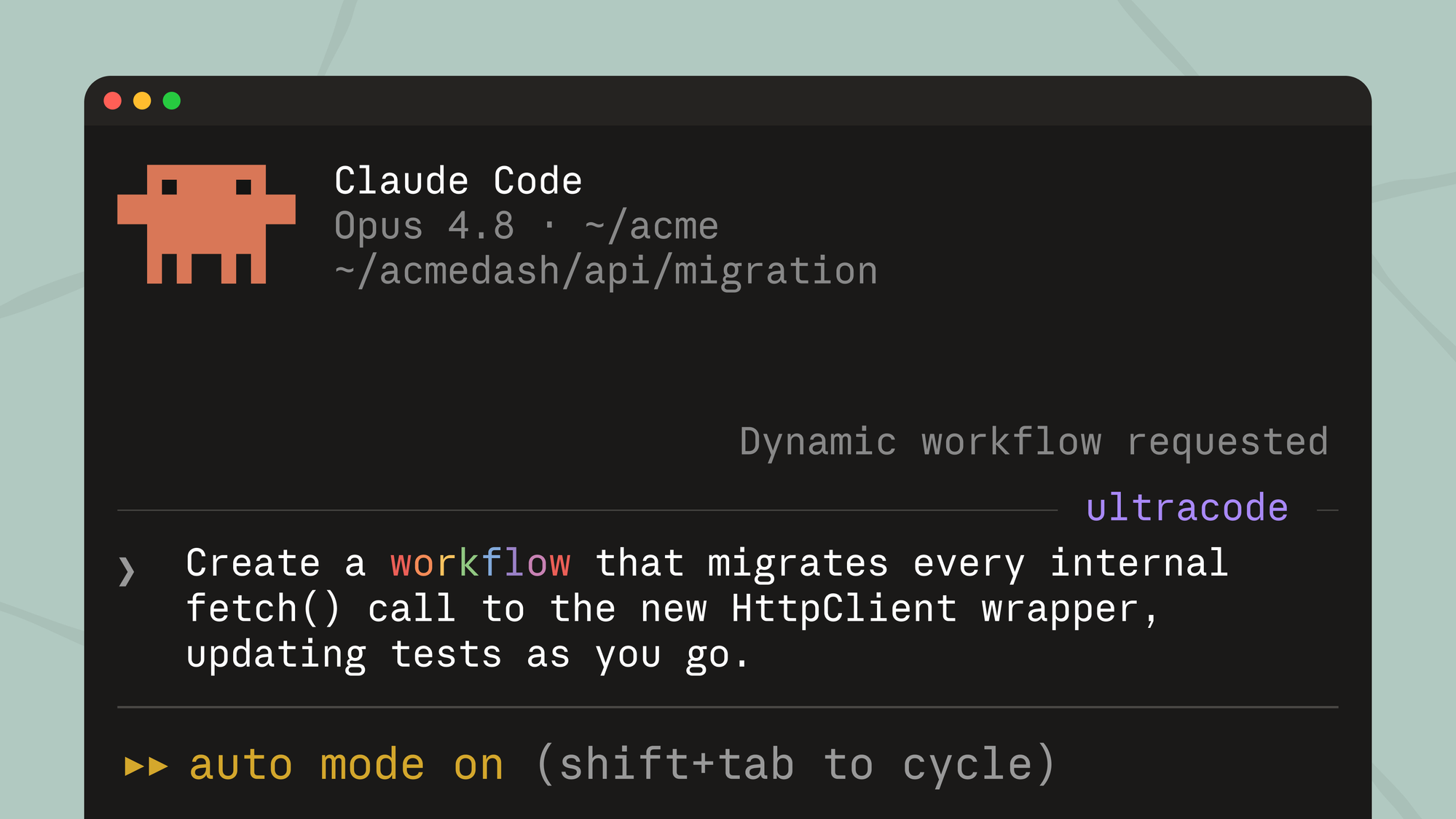
关键词触发:Prompt 中包含 workflow 或 ultracode 关键词。其中 ultracode 为 v2.1.160+ 新增,同时启用 xhigh 推理强度。也可用自然语言如 “use a workflow”。Claude 会编写工作流脚本而非逐步执行。误触发按 Alt+W 取消。
ultracode 模式:输入 /effort ultracode,结合 xhigh 推理强度 + 自动工作流编排。Claude 对每个实质性任务自动判断是否需要工作流。一个请求可能触发多个串行工作流(理解→修改→验证)。用 /effort high 随时回退。
内置工作流:/deep-research <问题> —— 多角度搜索 → 交叉验证来源 → 逐条投票 → 过滤未通过验证的声明 → 带引用报告。
已保存工作流:通过 /workflows → 按 s 保存到项目(.claude/workflows/,团队共享)或个人(~/.claude/workflows/),后续通过 /<name> 运行。支持 args 参数传入。
6.2 使用技巧
提示词:使用上述编排模式的术语(如”对抗性验证”“锦标赛”)进行具体提示,效果优于笼统描述。
与 /goal 和 /loop 结合:当使用可以重复的工作流时(如分诊、研究、验证),将它们与 /loop 配对以定期运行,与 /goal 配对以设置硬性完成要求。
Token 使用预算:可以为动态工作流设置明确的 token 使用预算来限制任务使用的 token 数量。用类似”使用 10k token”的预算来提示它,这将设置上限。
保存和分享:通过在工作流菜单中按 s 保存。可签入 ~/.claude/workflows 或通过 skill 分发——将 JavaScript 工作流文件放在技能文件夹中,并在 SKILL.md 中引用。为了更大的灵活性,可以提示 Claude 将技能中的工作流视为模板而不是需要逐字运行的脚本。
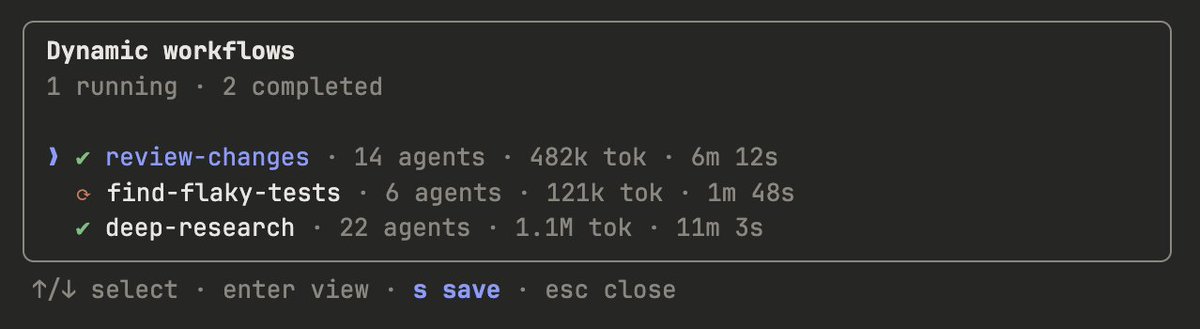
6.3 成本控制
官方建议:
- 先在小切片上运行(一个目录而非整个仓库),评估 Token 消耗
- 通过
/workflows实时监控进度和 Token 用量,随时可停止 - 对非关键阶段要求 Claude 使用更小模型(脚本中可指定
model参数) - 已完成的 Agent 结果被缓存,停止后不丢失
七、结论
核心判断
Dynamic Workflow 的本质不是”Claude 会开很多 Agent”,而是:
Claude 将编排决策外化为可执行的脚本代码,由独立运行时执行,从而突破单 Agent 循环的上下文、并行度和验证能力瓶颈。
这标志着 AI Coding 工具从”辅助编码”向”自主工程”的关键一步。目前主流竞品仍停留在单 Agent 循环或固定编排阶段。未来的竞争点将不仅是模型能力,更是谁拥有更强的编排运行时(Runtime)。